Machine learning can feel intimidating at first—lots of math, complex terms, and unfamiliar concepts. The good news? You don’t need to understand everything at once. By starting with the right machine learning algorithms for beginners, you can build a strong foundation and grow step by step.
What Is a Machine Learning Algorithm?
A machine learning algorithm is a set of rules that helps a computer learn patterns from data and make predictions or decisions without being explicitly programmed.
For example:
- Predicting house prices
- Recommending movies
- Detecting spam emails
Algorithms learn from data, improve with experience, and get better over time.
Types of Machine Learning Algorithms (Beginner Overview)
Before diving in, it helps to know the three main categories:
- Supervised Learning – Learns from labeled data
- Unsupervised Learning – Finds patterns in unlabeled data
- Reinforcement Learning – Learns through rewards and penalties
As a beginner, you’ll mainly start with supervised and unsupervised algorithms.
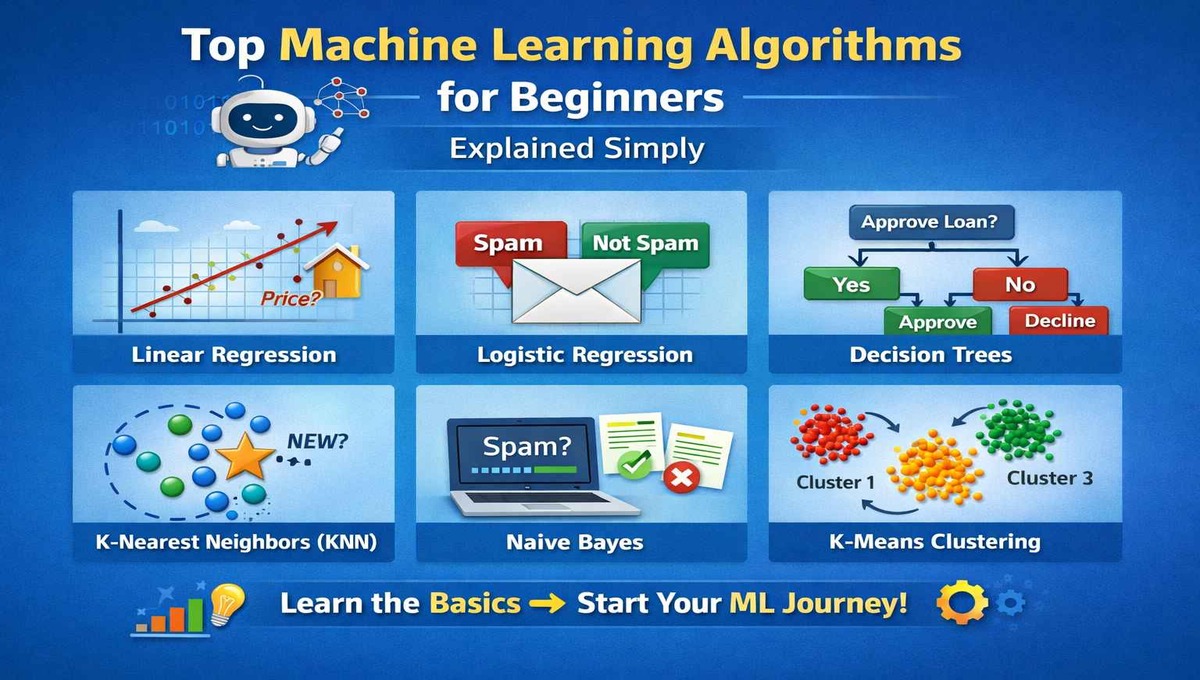
1. Linear Regression
Best for: Predicting numerical values
Linear Regression is one of the simplest and most popular machine learning algorithms for beginners.
Simple Example:
Predicting a house price based on size.
Why it’s beginner-friendly:
- Easy to understand
- Great introduction to prediction problems
- Widely used in real-world applications
2. Logistic Regression
Best for: Binary classification (Yes/No, True/False)
Despite the name, Logistic Regression is used for classification, not prediction of numbers.
Simple Example:
- Is an email spam or not?
- Will a customer buy or not?
Why beginners should learn it:
- Simple logic
- Foundation for more advanced classifiers
- Common in business analytics
3. Decision Trees
Best for: Classification and regression
Decision Trees work like a flowchart—making decisions step by step.
Simple Example:
- Should a loan be approved?
- Which product should be recommended?
Why it’s great for beginners:
- Easy to visualize
- Minimal data preparation
- Works well with both numbers and text
4. K-Nearest Neighbors (KNN)
Best for: Classification problems
KNN makes predictions based on similar data points.
Simple Example:
If most nearby movies are action, a new movie might also be classified as action.
Beginner benefits:
- Very intuitive
- No complex training process
- Great for understanding similarity-based learning
5. Naive Bayes
Best for: Text classification and spam detection
Naive Bayes is based on probability and works surprisingly well despite its simplicity.
Simple Example:
Classifying emails as spam or not spam.
Why beginners love it:
- Fast and efficient
- Excellent for text-based data
- Easy to implement
6. Support Vector Machine (SVM)
Best for: Classification with clear boundaries
SVM separates data into classes by finding the best possible boundary.
Simple Example:
Separating fraudulent and non-fraudulent transactions.
Why beginners should try it:
- Powerful for small to medium datasets
- Works well for complex classification tasks
7. K-Means Clustering
Best for: Unsupervised learning
K-Means groups data into clusters based on similarity.
Simple Example:
Customer segmentation in marketing.
Beginner advantages:
- Easy to understand clustering
- No labeled data required
- Common in real-world analytics
Which Algorithm Should Beginners Learn First?
If you’re just starting, follow this order:
- Linear Regression
- Logistic Regression
- Decision Trees
- KNN
- Naive Bayes
- K-Means
This progression builds confidence and understanding gradually.
Tools to Practice Machine Learning Algorithms
Beginners should focus on these tools:
- Python
- Scikit-learn
- Pandas
- Jupyter Notebook
They make learning machine learning algorithms much easier and more practical.
Final Thoughts
Learning machine learning doesn’t have to be overwhelming. By focusing on these top machine learning algorithms for beginners, you’ll gain clarity, confidence, and real-world skills.



